
이번 포스트에서는 저번 포스트에 이어 데이터프레임으로 받아온 ASOS 지점 자료를 데이터베이스에 저장하는 방법을 기록하고자 합니다.
1. 데이터베이스 구축하기
파이썬의 sqlite3 모듈을 활용하여 내 로컬 폴더에 데이터베이스 (DB)를 생성합니다.
1
2
3
4
import os
import requests
import pandas as pd
import sqlite3
1
2
3
4
5
6
DB_DIR = 'DB'
DB_TBL = 'ASOS_Hourly' # DB file and table name
if not os.path.isdir(DB_DIR):
os.makedirs(DB_DIR)
con = sqlite3.connect(DB_DIR+'/'+DB_TBL+'.db')
cur = con.cursor()
2. ASOS 데이터프레임 자료 DB에 저장하기
지난 포스트에서 생성한 ASOS 자료의 데이터프레임 (df)를 ASOS_Hourly.db에 저장합니다. 지금은 데이터베이스에 아무 자료도 저장되어 있지 않기 때문에 그대로 넣어주면 됩니다.
{kind=link}
1
df.to_sql(DB_TBL, con, schema=None, if_exists='append', index=False, index_label=None, chunksize=10000, dtype=None)
옵션에 대한 자세한 설명은 pandas reference에서 확인할 수 있습니다.
그리고 이 DB에 중복된 데이터가 들어오지 못하도록 unique index를 설정해줍니다. 이에 대한 자세한 내용은 아래에 설명하겠습니다.
1
cur.execute('CREATE UNIQUE INDEX IF NOT EXISTS idx_unique ON '+DB_TBL+' (TM,STN)')
3. DB에 저장된 기존 자료들과 중복되지 않는 ASOS 자료만 DB에 저장하기
연구 할 때 마다 필요한 기간의 데이터만 조금씩 받아오게 되면, 기존에 보유하고 있던 데이터와 중복되는 경우가 종종 있죠. 보통 기상 데이터는 30년 이상 긴 기간의 데이터를 사용하게 되는데 중복되는 경우를 하나하나 확인할 수는 없습니다. 따라서 이번에는 기존에 데이터베이스에 저장된 ASOS 자료와 중복되지 않는 데이터만 저장하는 파이썬 코드를 작성해보고자 합니다.
우선 데이터베이스에 기존에 저장되어 있던 자료를 불러옵니다.
1
existing_df = pd.read_sql_query('SELECT TM, STN FROM '+ DB_TBL, con)
다음으로, 새로 저장을 할 데이터프레임을 new_df 라고 하겠습니다. existing_df는 2023.08.01 00LST ~ 2023.08.01 23LST 기간의 전체 ASOS지점 데이터이고, new_df는 2023.08.01 10LST~ 2023.08.02 23LST 기간의 전체 ASOS지점 데이터 입니다.
ASOS 자료는 시점 (TM)과 ASOS 지점번호 (STN)에 대해 각기 다른 기상관측 자료들이 존재합니다. 다시 말해, TM과 STN의 조합은 ASOS 자료 내에서 고유번호로 볼 수 가 있다는 것입니다. 이를 이용하여 앞서 데이터베이스 테이블에 unique index를 설정하였습니다. 설정 이후에 (TM,STN)의 조합이 중복되는 데이터를 DB에 저장하려고 시도할 경우에는 에러가 발생하게 됩니다.
중복 데이터를 제거하는데 TM과 STN의 조합을 활용하고자 합니다. ['TM','STN']조합으로 새로운 인덱스를 만들어 existing_df와 중복되지 않는 new_df의 자료만 추출합니다.
1
2
3
4
existing_index = existing_df.set_index(['TM', 'STN']).index
new_index = new_df.set_index(['TM', 'STN']).index
unique_index = ~new_index.isin(existing_index)
unique_df = new_df[unique_index]
위의 코드를 한 줄로 만들면 이렇게 됩니다.
1
unique_df = new_df[~new_df.set_index(['TM', 'STN']).index.isin(existing_df.set_index(['TM', 'STN']).index)]
코드를 실행시켰을때, new_df 와 unique_df 는 다음과 같이 나옵니다.
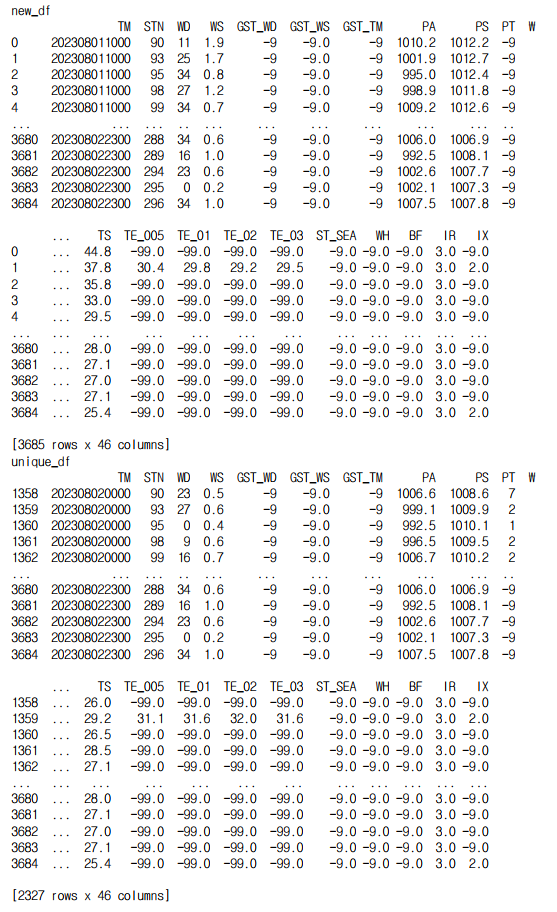
그리고 unique_df를 앞서 설명한 .to_sql을 활용해 DB에 저장하면 됩니다.
이를 통합시켜서, DB에 해당 테이블이 있을 경우에는 받아온 데이터를 그대로 저장하고 unique index를 만들고, 아닌 경우에는 중복 데이터를 제거한 데이터를 DB에 저장하는 파이썬 if 문을 아래에 만들어 보았습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
check = f'SELECT COUNT(*) FROM sqlite_master WHERE type="table" AND name="{DB_TBL}"' # Check if table exits
cur.execute(check)
check_result = cur.fetchone()
if not check_result[0]:
df.to_sql(DB_TBL, con, schema=None, if_exists='append', index=False, index_label=None, chunksize=10000, dtype=None)
cur.execute('CREATE UNIQUE INDEX IF NOT EXISTS idx_unique ON '+DB_TBL+' (TM,STN)')
con.commit()
else:
existing_df = pd.read_sql_query('SELECT TM, STN FROM '+DB_TBL, con)
unique_df = df[~df.set_index(['TM', 'STN']).index.isin(existing_df.set_index(['TM', 'STN']).index)] #Find not duplicate data
unique_df.to_sql(DB_TBL, con, schema=None, if_exists='append', index=False, index_label=None, chunksize=10000, dtype=None)
con.close()
다음 포스트에서는 기상청 API허브에서 격자 데이터를 받아와 netcdf파일로 저장하는 방법을 기록하도록 하겠습니다.